Оглавление:
| Expand | ||||
|---|---|---|---|---|
| ||||
|
Описание
Данный блок служит различным манипуляциям экшен служит для различных манипуляций с текстом, которые в практике требуются очень часто. Обработать спарсенный текст, очистить его от мусора, перевести на другие языки – всё это, и многое другое, может «кубик» обработки текста.
...
Как добавить действие в проект?
Через контекстное меню Добавить действие → Данные → Обработка текста
...
Либо воспользуйтесь умным поиском.
Где применяется обработка текста?
Escape строки. Для экранирования специальных символов
Regex. Поиск текста регулярным выражением
Spintax. Рандомизировать, уникализировать текст
Split. Разделить строку на несколько других через разделитель
ToChar. Преобразовать Unicode код в символ
ToLower, ToUpper. Преобразовать заглавные буквы в строчные и наоборот
Trim. Очистить текст от лишних пробельных символов
UrlEncode, UrlDecode. Кодировать \ Декодировать URL
В переменную, список, таблицу. Положить данные в переменную, список или таблицу
Замена. Произвести замену в тексте
Перевод. Выполнить перевод на другой язык
Подготовка JavaScript. Обработать текст для использования в экшене Логики (IF-ELSE) или JavaScript
Транслитерация. Сделать транслитерацию текста
Как
...
работать с экшеном?
Окно свойств состоит в основном из трёх областей:
...
| Info |
|---|
Установите курсор в области входной строки, нажмите Ctrl+Пробел и выберите из выпадающего списка полезные константы и переменные проекта. Например, так можно быстро вставить прокси проекта |
...
Все возможные операции с этим «кубиком»:
Escape строки
Экранирование символов.
Этот экшен заменяет экранирует пробел и символы *+?|{[()^$.# и пробел escape-кодами (размещает “слэш” перед каждым указанным символом - \) . Этот метод часто используется для работы с запросами и для того чтобы обработчик регулярных выражений использовал эти символы буквально, а не как команды или метасимволы.
До применения: {"animal": "cat"}
После: \{"animal":\ "cat"}
...
Regex
...
Обработка текста регулярными выражениями.
Регулярками очень удобно парсить строки для нахождения нужной подстроки по заданному паттерну. Данный экшен позволяет спарсить не только первое найденное значение, но и всю группу и сохранить значения в переменные или таблицу. Также, опционально, если ничего не найдено, результатом будет ошибка и выход по красной ветке. Всего имеется шесть вариантов сохранения результатов после обработки регулярным выражением:
сохраняется только первое найденное значение;
сохраняются все найденные соответствия в список;
сохраняется одно значение, но или последнее или случайное;
сохраняются одно или несколько значений в список, но определенного индекса (порядковому номеру в списке найденных значений). Индексы можно перечислить через запятую (4,5,9), задать интервал через дефис (4-9) или комбинацией вышеуказанных способов (4,5, 9-11);
тоже самое что в предыдущем пункте, но без списка, а значение каждого найденного индекса можно положить в свою переменную;
совпадения сохраняются в таблицу.
Для создания паттернов регулярных выражений в ZennoPoster предусмотрен очень удобный инструмент – Конструктор регулярных выражений.
Рассмотрим на конкретном примере .
Поле ввода “Regex”
В данное поле необходимо ввести регулярное выражение, с помощью которого будет производиться поиск по тексту. Пример - (?<=<title>).*(?=</title>)
В составлении регулярных выражений Вам может помочь Тестер регулярных выражений
Ошибка при пустом ответе
Если отмечена данная настройка и регулярное выражение ничего не нашло в тексте, то экшен завершится ошибкой (выход по красной ветке).
| Note |
|---|
Обратите внимание на то, что если регулярное выражение вернёт пустую строку, то даже при включённой настройке “Ошибка при пустом ответе” экшен выйдет по зелёной ветке: например, на сайте ничего нет в теге title: |
Что брать
Первое
В переменную сохранится первое найденное совпадение.
Все
Сохранить все результаты поиска в список.
Одно совпадение
Сохранить только одно совпадение.
В появившемся поле можно ввести порядковый номер совпадения (нумерация с нуля!) или выбрать Последнее либо Random (случайное) значение.
...
Номера совпадений
Сохранить в список только указанные номера совпадений (нумерация с нуля!, указывать через запятую).
В переменные
Данная функция используется при работе с групповыми регулярными выражениями. Пример под спойлером:
| Expand | |||||
|---|---|---|---|---|---|
| |||||
Представим, что есть следующий текст:
И стоит задача его разобрать на составляющие. Для этого воспользуемся таким регулярным выражением: Вот как результат выполнения выглядит в Тестере регулярных выражений: 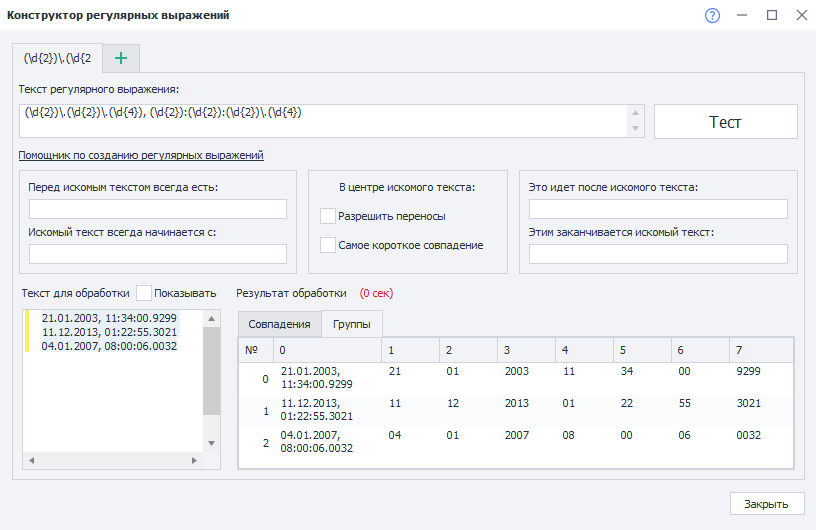 Представим, что нам надо взять в переменные день, месяц и год из второй строки. Вот как это можно сделать: 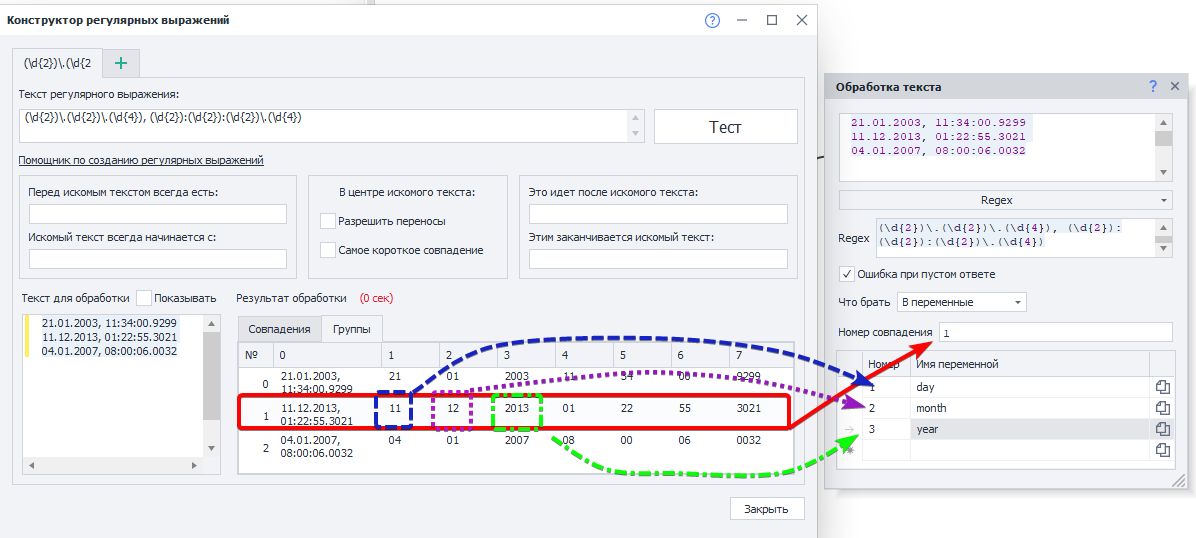 Номер совпадения в нашем случае - номер строки. Т.к. нумерация тут начинается с нуля, то для того, чтобы взять вторую строку, указываем 1 Дальше надо указать номер группы и переменную, в которую сохранится результат. Тут тоже нумерация групп начинается с нуля. Но в группе 0 находится вся найденная строка ( |
В таблицу
Очень похоже на предыдущую функцию (В переменные) с тем отличием, что тут сохраняется не один результат, а все и в таблицу. Можно исключить из итогового результата некоторые найденные группы.
| Expand | |||||
|---|---|---|---|---|---|
| |||||
Используем тот же текст:
Перед нами стоит задача его разобрать и сохранить в таблицу. Для этого воспользуемся таким регулярным выражением: Вот как результат выполнения выглядит в Тестере регулярных выражений: Так же представим, что в итоговой таблице нам не нужны секунды и миллисекунды. Вот как это может выглядеть: 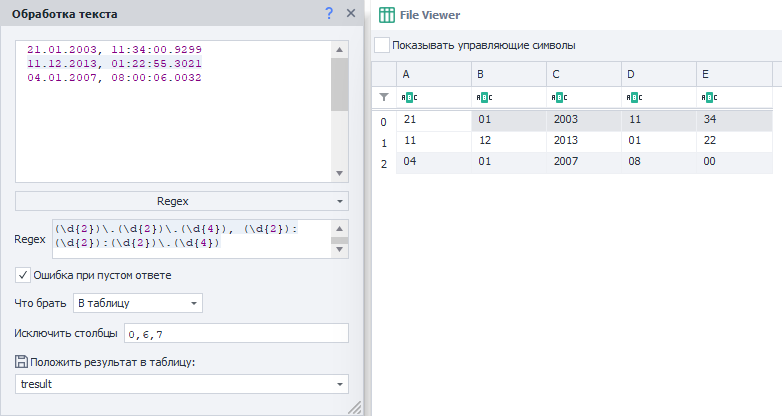 В группе под индексом 0 находится всё совпадение (в нашем случае строка) поэтому исключаем. В группах 6, 7 - секунды и миллисекунды соответственно. |
Пример использования
Рассмотрим на конкретном примере - парсинг ссылок регулярными выражениями, составленными с помощью этого конструктора.
Например, у нас есть задача - спарсить получить ссылки на профили активных пользователей форума ZennoLab. Приступаем:
...
С помощью кубика “Получение значения” Взятие значения получаем HTML код элемента в котором размещены ссылки на пользователей находящихся на форуме онлайн.
Добавляем экшен “Regex”. Для составления паттерна, используемого в свойствах экшена “Regex”, используем Конструктор регулярных выражений.
В свойствах экшена на вход добавляем переменную “html“, а результат сохраняем в список “urls“.
После запуска кубика получаем в списке уникальные id, которые можно использовать для формирования URL профилей юзеров.
...
Spintax
Рандомизация или уникализация текста.
С помощью spintax удобно создавать синонимизацию текстов. Спинтакс - это такая конструкция из обрамляющих фигурных скобок и вертикальных слэшей, которая позволяет в случайном порядке подставлять подстроки из строки. В простейшем варианте спинтакс выглядит так: {вариант1|вариант2|вариант3}. При выполнении этого действия в результирующую переменную случайно попадет один из трёх вариантов.
Но конструкции спинтакса бывают более сложными и обладают многоуровневой вложенностью из-за чего из одного текста можно получить тысячи разных вариантов.
...
...
Расширенный синтаксис спинтакса
{Red|White|Blue}— в результирующий текст попадает одно из значений, например: «White»[ Red| White| Blue]— в результирующий текст попадает перестановка значений, например: «White Blue Red»[+_+Red|White|Blue]— в результирующий текст попадает перестановка значений, между которыми вставлен разделитель, например: «White_Red_Blue»
Вложенность шаблонов неограниченна (например: [+{_|-}+Red|White|Blue {1|2}] = «White-Blue 2-Red»). Спец.символы можно экранировать: [+\++Red|\[White\]|Blue] - результат «[White]+Red+Blue»
...
Split
Разделение текста каким-либо символом-разделителем (делиметером).
Эта обработка превращает строку в массив строк. По сути это более простой аналог RegExp для разделения строки символами.
Разделители
Здесь нужно указать символ (-ы), по которому будут разбиваться данные.
Рассмотрим работу сплита на примере очень частой задачи – получение из строки логина и пароля. Обычно доступы к различным аккаунтам хранятся в виде построчных списков в формате - логин:пароль. И тут делиметором является символ двоеточия :
...
Вставляем в входное поле нашу строку или переменную её содержащую. В свойствах указываем разделитель - :, а ниже присваиваем каждому элементу полученного массива подстрок отдельную переменную. После обработки строки мы получаем в каждой переменной логин и пароль.
...
...
Разрешить пустые значения
Этот пункт рассмотрим на примере.
И так у нас есть строка в формате имя;фамилия;пол;год рождения Экшен может выглядеть так:
...
Но, если будет отсутствовать одна из составляющих, например пол (Андрей;Павлов;;1988), то год рождения запишется в переменную для пола (sex ). Вот как раз для таких случаев и создана настройка Разрешить пустые значения - если её включить, в переменную для пола запишется пустая строка, а год сохранится в правильную переменную.
Пример использования
Рассмотрим работу сплита на примере очень частой задачи – разбиение строки с прокси на составляющие части. Очень часто покупные прокси имеют такой формат: логин:пароль@хост:порт
Тут сразу два разделителя - :(двоеточие) и @. Вот как могут выглядеть настройки экшена:
...
В качестве разделителя здесь указаны сразу оба символа.
...
ToChar
Преобразует значение целого числа в символы Unicode.
Каждый символ Юникод имеет свой цифровой код и этот функционал позволяет конвертировать числовое значение в соответствующие символы. Например у символа ♛ числовое значение 9819
...
ToLower
...
Меняет регистр букв на нижний в зависимости от выбранного свойства: либо все буквы, либо только первую букву строки, либо первую букву в каждом слове.
Например нас ОЧЕНЬ РАЗДРАЖАЕТ НАПИСАНИЕ CAPS LOCKОМ. Пропускаем текст через этот макрос и получаем нормальное написание.
...
ToUpper
Обратное действие предыдущего. Меняет регистр букв в верхний: либо все буквы, либо только первую букву строки, либо первую букву в каждом слове.
Например, нам нужно Чтобы Все Слова В Заголовке Начались С Заглавных Букв (частый приём на иностранных ресурсах) - используем этот “кубик” в режиме “Первая буква в каждом слове“.
...
Trim
Это обрезка лишних символов в строке. В основном . Для примера возьмём строку МЕНЯЕТ РЕГИСТР БУКВ НА НИЖНИЙ
Все
Заменит все символы верхнего регистра в тексте на нижний регистр.
Было | Стало |
|---|---|
МЕНЯЕТ РЕГИСТР БУКВ НА НИЖНИЙ | меняет регистр букв на нижний |
Начало слов
Меняет регистр на нижний у первого символа каждого слова в тексте.
Было | Стало |
|---|---|
МЕНЯЕТ РЕГИСТР БУКВ НА НИЖНИЙ | мЕНЯЕТ рЕГИСТР бУКВ нА нИЖНИЙ |
Первый символ
Меняет регистр только первого символа в переданном тексте.
Было | Стало |
|---|---|
МЕНЯЕТ РЕГИСТР БУКВ НА НИЖНИЙ | мЕНЯЕТ РЕГИСТР БУКВ НА НИЖНИЙ |
...
ToUpper
...
Меняет регистр букв на верхний в зависимости от выбранного свойства. Для примера возьмём строку текст в нижнем регистре
Все
Заменит все символы нижнего регистра в тексте на верхний регистр.
Было | Стало |
|---|---|
текст в нижнем регистре | ТЕКСТ В НИЖНЕМ РЕГИСТРЕ |
Начало слов
Меняет регистр на верхний у первого символа каждого слова в тексте.
Было | Стало |
|---|---|
текст в нижнем регистре | Текст В Нижнем Регистре |
Первый символ
Меняет регистр только первого символа в переданном тексте.
Было | Стало |
|---|---|
текст в нижнем регистре | Текст в нижнем регистре |
...
Trim
Эта функция используется для удаления лишних символов в начале и\или конце переданной строки.
Чаще всего используется, если нужно почистить строку от лишних пробелов, переносов строк, табуляций, которые так часто остаются в результате парсинга. При этом чистить можно с начала строки, с конца и одновременно. Кроме того, обрезать можно и свои символы, например частая задача - удалить точки в заголовках.
Было: какой-то текст (пробелы в начале и в конце)
Стало: какой-то текст
UrlDecode
Декодирует URL-закодированную строку.
Если такие символы, как пробелы и знаки препинания, передаются в HTTP-запросе, то они могут быть неверно интерпретированы в принимающей стороне. Поэтому данный макрос обязательно используется при формировании URL-запросов.
.
Что обрезать
Тут необходимо выбрать символы, которые нужно удалить. Это может быть либо предустановленный вариант для всех типов пробельных символов (пробел, перенос строки, табуляция), либо Вы можете указать свои символы.
Где обрезать
Где надо удалить символы - Начало строки, Конец либо Начало и Конец.
...
UrlDecode
Декодирует закодированную с помощью UrlEncode (описано ниже) строку.
Наиболее наглядно этот экшен выглядит при раскодировании кириллицы:
Было: %D0%9F%D1%80%D0%B8%D0%B2%D0%B5%D1%82%2C%20%D0%BC%D0%B8%D1%80%21
Стало: Привет, мир!
...
UrlEncode
Функция обратная предыдущей. Кодирует строку URL-адреса. Часто используется для HTTP-запросов.
Было: https://zennolab.com/
Стало: https%3a%2f%2fzennolab.com%2f
...
В URL разрешается использовать лишь латинские буквы, цифры и несколько знаков пунктуации. Все остальные символы, которые передаются в HTTP-запросе, должны быть закодированы с помощью UrlEncode, иначе сервер может неправильно интерпретировать запрос.
Кодировать только значения в переменных
Очень удобно использовать при формировании HTTP запросов, т.к. адрес сайта кодировать не надо, а только параметры. Вот как могут выглядеть настройки экшена:
...
В переменной {-Variable.keyword-}находится текст что такое urlencode. После выполнения в переменную {-Variable.url-} запишется такая строка - https://www.google.com/search?q=%d1%87%d1%82%d0%be+%d1%82%d0%b0%d0%ba%d0%be%d0%b5+urlencode
...
В переменную
Это действие просто сохраняет всё что вы добавите во входное окно – переменные, текст, символы, константы проекта, в отдельную переменную.
...
В список
Данный экшен разбивает текст с помощью указанного в свойствах разделителя на строки и записывает их в список.
Разделитель
Enter - символ новой строки
Пробел
Свой текст - тут можно указать как единичный символ (например
;) так и несколько символов (внимание: если Вы укажите здесь несколько символов, то они будут рассматриваться как один разделитель!)Свой Regex - использование регулярного выражения.
...
В таблицу
Примерно тоже самое что и в предыдущем экшене, но сохраняет данные в таблице. Естественно, в данном случае необходимо указать разделители не только для строк, но и для столбцов. Например для таблиц в формате Excel нужно указывать разделителем столбцов свой символ и ввести в поле рядом {-String.Tab-}
Замена
Данное действие разбивает переданный текст на строки и столбцы (согласно указанным разделителям) и помещает данные в таблицу.
Разделители
Enter - символ новой строки
Пробел
Свой текст - тут можно указать как единичный символ (например
;) так и несколько символов (внимание: если Вы укажите здесь несколько символов, то они будут рассматриваться как один разделитель!)Свой Regex - использование регулярного выражения.
...
Замена
...
Это действие ищет в строке подстроку, заменяет её на другую и затем сохраняет результат в переменную. Вроде бы всё просто, но благодаря возможности использования регулярных выражений потенциал этого экшена сильно расширяется. Также как и в других действиях можно заменять не только первое найденное совпадение, но все или заданные индексы (перечисленные через запятую или диапазон заданный дефисом).
...
Что искать
Подстрока, которую надо найти (либо регулярное выражение, если выбран тип поиска Regex).
На что заменить
Чем будет заменена найденная подстрока.
Тип поиска
Text - ищется точно такая же строка, которая была передана в поле Что искать.
Regex - в поле Что искать надо записать регулярное выражение, по которому будет искаться совпадение.
Что заменять
Первое
Будет заменено первое найденное совпадение.
Все
Будут заменены все совпадения.
Одно совпадение
Заменить только одно, указанное, совпадение (нумерация с нуля!) либо Последнее.
Номера совпадений
Указать через запятую номера совпадений, которые нужно заменить (нумерация с нуля!).
...
Перевод
Переводит строки с одного языка на другой.
...
В экшене перевода имеется большой выбор сервисов перевода, что поможет гибко подходить к уникализации текстов выбирая наиболее качественные текста.Доступны следующие API
Сервис перевода
Тут необходимо выбрать сервис, через который будет осуществляться перевод. Доступные варианты:
Кроме выбора API, которое будет переводить, важно указать язык оригинала и итогового перевода. Ключи API для сервисов можно добавить в настройках ZennoPoster.
Язык оригинала, Язык назначения
С какого и на какой язык надо перевести текст.
Вот несколько примеров: английский – en, испанский – es, немецкий – de, русский – ru (полный список)
| Note |
|---|
Коды языков могут отличаться в разных сервисах. Для полного и достоверного списка кодов стоит обратиться к документации выбранного сервиса. |
Можно указать язык “auto” и тогда система попробует определить язык перевода сама, но результат не гарантируется.
Дополнительными параметрами можно значительно расширить возможности этого «кубика», но они у каждого API свои собственные. Например, передачей ключа API можно добиться более стабильной работы переводчика.
Ключи API для сервисов можно добавить в настройках ZennoPoster.
...
Дополнительные параметры
Дополнительные параметры, которые можно передать стоит уточнить в документации выбранного сервиса.
Использовать прокси проекта (если это возможно)
Если это возможно, то запрос на перевод будет осуществлён с помощью текущего установленного прокси.
Подготовка JavaScript
Обрабатывает строку для корректного использования в JavaScript. В основном экранирует кавычки и другие спец. символы. Этот макрос подготавливает текст, чтобы его можно было вставить в качестве строки в экшен JavaScript или IF. В ProjectMaker есть тестер JavaScript, где можно проверить (протестировать) код. Этот “кубик” поможет заэкранировать кавычки, апострофы и другие спецсимволы.
Было: <a href="https://zennolab.com/">
Стало: <a href=\"https://zennolab.com/\">
...
Подстрока
Берет из строки кусок текста заданный в свойствах экшена двумя индексами – от одного символа и до другого. Например, если взять первое предложение этого абзаца и есть задача получить подстроку в ней от 95 символа до конца текста, то получим “до другого.“ .
...
Транслитерация
Иногда всё ещё требуется perevesti кириллицу в латиницу. Этому действию и служит данный экшен.
...